Datos
Hemos capturado todos los tweets que contenían una serie de palabras clave, tanto en el cuerpo del texto como en hashtags, desde la fecha de comienzo del proyecto. Dado que capturamos también retweets, algunos de estos tienen fecha anterior al comienzo de las capturas de tweets emitidos.
Para fijar la notación a lo largo de este texto, consideremos un tweet típico:
(@pepito) Este es un tweet de prueba, para @fulanito, que debería ver esta página http://www.myhome.com. Mírala antes de la #finaldecopa
- @pepito: Emisor (único y obligatorio)
- @fulanito: Receptor (puede haber varios o ninguno)
- "Este es un tweet...": Cuerpo del mensaje
- http://www.myhome.com: Link
- #finaldecopa: Hashtag (varios o ninguno)
Si bien hasta hace poco era habitual limitarse a los hashtags a la hora de realizar búsquedas y estadísticas, ahora es política de twitter incluir el texto entre los estudios de tendencias. Nosotros hemos seguido esta línea y consideramos tanto hashtags como apariciones en el texto sin distinción.
Volver arriba
Pestaña Estadísticas
La lista de palabras clave fue fijada inicialmente a un conjunto determinado por la inspección directa de las redes sociales e Internet. A partir de este conjunto inicial, y tras la captura de varias decenas de miles de tweets, se buscaron palabras claves y hashtags nuevos que aparecieran con frecuencia, y se incluyeron en la lista de rastreo, realizándolo de nuevo retrospectivamente desde el día fijado. Este rastreo en fechas pasadas puede hacerse gratuitamente sólo en una semana.
Procedimiento de captura y almacenamiento
Dada la lista de palabras clave, capturamos todos los tweets que contengan al menos una palabra de la lista. De dichos tweets extraemos todos los emisores y receptores, formando nuestro conjunto de usuarios. Su número puede verse en la pagina anterior, y va creciendo con el tiempo. Extraemos asi mismo todas las links mencionadas.
Retweets
Capturamos también los retweets que contienen alguna palabra clave, guardando la información del creador (primer emisor) del tweet y del número total de veces que ha sido retweetado.
Estadisticas
Pueden verse los listados de palabras claves rastreadas, número de tweets, etc...
Primeros filtros
Automenciones:
Una práctica habitual para generar ruido es crear tweets donde el emisor se cita a si mismo. Hemos eliminado las menciones realizadas por un emisor a si mismo, si bien mantenemos el resto de menciones caso de haberlas.
Apariciones colaterales
Las palabras clave seleccionadas son usadas en otros contextos absolutamente diferentes. Un ejemplo de la cantante “Lana del Rey”, con millones de seguidores, que además es nombrada con frecuencia como "reina".
Otro caso es el movimiento opositor en Venezuela, que hablan con frecuencia de "dictadura".
Un análisis puramente estadístico no da pistas ni herramientas para un filtrado a este nivel. Veremos que el análisis de redes permite comprender, visualizar y finalmente eliminar estas lineas de opinión.
Citas generales
Hay usuarios que aparecen debido a su carácter generalista, por ejemplo youtube, pues hay numerosas referencias a videos en los tweets.
Volver arriba
Pestaña Gráficos
Se muestran la evolucion temporal de hashtags y menciones.
Si seleccionamos "hashtags ALL, Usuario ALL" se genera una grafica donde aparece el total de hashtags capturados en periodos de X horas. Cuando seleccionamos un hashtag concreto sólo aparece el numero de apariciones de ese hashtag concreto, en un tweet de cualquier emisor.
Si seleccionamos un hastag concreto, y un emisor concreto, se visualiza el número de apariciones de ese hashtag emitidos por el usuario seleccionado.
Pueden superponerse varias gráficas para comparar la actividad.
Volver arriba
Pestaña Mapa de Calor
Podemos extraer información de donde han sido emitidos los tweets, para posicionarlos sobre un mapa y estudiar su distribucion geografica.
Hay dos formas de geoposicionar un tweet
- Algunos tweets contienen información de la geoposición en el momento de su creación.
- Si no disponemos de la información del tweet concreto, usamos la información de ubicación del usuario de su registro en twitter.
El porcentaje de tweets que pueden geoposicionarse por alguno de los dos puntos anteriores es del orden del 7.2% (El dia 18, un total de 189336 sobre 2.635.015).
Una vez obtenida la información, podemos dibujar sobre el mapa el punto donde se ha emitido.
Cuando hay muchos tweets superpuestos, con un código de color visualizamos hacemos una correspondencia con la densidad de los mismos.
Es posible ver la geoposición de todos los tweets, o seleccionar los que contienen una cierta palabra clave.
Volver arriba
Pestaña Comunidades
Aquí construimos la Red de Relaciones entre todos los implicados en el movimiento asociado a la Abdicacion, en twitter.
Esta Red puede verse desde muchos puntos de vista, como corresponde a una rica estrucutura de relaciones, permitiendo un estudio a fondo del conjunto, desde el punto de vista de sus propiedades colaborativas, más alla de las propiedades individuales, ya mostradas en las Estadisticas. De este modo aquí nos preocupamos de preguntas como:
- ¿Qué personas son las de mayor importancia en la Red?
- ¿Y las de mayor autoridad?
- ¿Qué grupos se forman? ¿Cuáles son los de mayor impacto?
- ¿Qué grupos o personas están aisladas?
- ¿A quién debo de influir para llegar a toda la Red?
- Etc.
Nodo y Relaciones
Para crear un mapa las dos cuestiones fundamentales son:
- Conjunto de Nodos a representar.
- Qué relaciones establecemos entre ellos.
Conjunto de nodos
- Los N más mencionados: En este caso seleccionamos los N usuarios que han recibido más de N menciones en el conjunto total de tweets. Estos Mapas contienen pues a las personas más citadas, las que más "suenan".
- Mencionadores de un Usuario: Por ejemplo si seleccionamos "Usuarios de El País", en este mapa se muestran todos aquellos usuarios que en algún tweet emitido por ellos, han mencionado a El País.
Relaciones
Una vez fijado el conjunto de usuarios, ahora debemos decir como son las relaciones entre ellos. En este caso, diremos que un usuario esta relacionado con otro si lo ha mencionado en algún tweet.
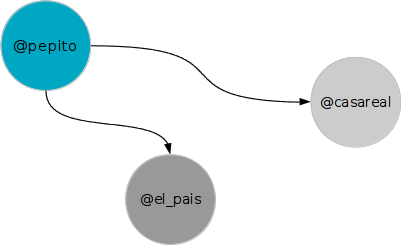
Supongamos un tweet como éste:
(@pepito) Estoy muy interesado en el tema de la #abdicacion y lo que dicen en la @casareal y lo que comentan en @el_pais
El emisor es @pepito y menciona a @casareal y a @el_pais.
Creamos pues una relación entre estos dos usuarios, que apunta de @pepito a @casareal y de @pepito a @el_pais. Es decir, tendríamos el siguiente diagrama:
Tras establecer la relación debemos fijar su intensidad. Por ejemplo no es lo mismo que pepito menciona a casareal una vez y a El País 100; en este caso la relacion deberia ser más estrecha con El País que con la casareal, y por tanto sería razonable que aparecieran más cerca del primero que del segundo.
Pero tambien podemos usar otros criterios, como por ejemplo el número de retweets del tweet objeto de la mención. Por ejemplo si pepito menciona una vez solo a la casareal, pero este tweet tiene un gran éxito y se retweetea miles de veces, deberian aparecer más juntos que otras relaciones que no se hayan retweeteado. Son visiones complementarias, y ambas posibles.
Las relaciones las construimos siempre asi:
Dos usuarios están relacionados si uno (emisor) cita a otro (receptor). La relación es dirigida del emisor al receptor, y la fuerza de la union es proporcional al número total de menciones.
Podemos construir mapas diferentes de acuerdo con la intensidad asignada a estas relaciones:
- Mapa de menciones: Intensidad de cada link: Numero total de Menciones. Tamaño de cada usaurio en el mapa: Numero total de menciones recibidas.
- Mapa de Retweets: Intensidad de cada link: Numero de retweets del tweet en cuestion. Tamaño del usuario en el mapa: Numero total de retweets de los tweets emitidos por el usuario.
Nota importante:
Para ver la diferencia (importante) con el mapa de menciones y grado, consideremos un ejemplo con un caso real.
La @casareal emitio un tweet en el cual felicitaba al @realmadrid por su copa de europa.
El emisor es la @casareal, el receptor el @realmadrid.
En nuestro criterio, quien recibe el mérito es siempre el usuario citado, no el que cita, pues es evidente que los importantes son los citados (en caso contrario, los generadores de spam dominarían la red).
Este tweet crea una relación entre @casareal y @realmadrid.
El @realmadrid no aparece en casi ningún tweet más de nuestra muestra, como es normal.
Por tanto, dado que nadie más lo menciona, en el mapa anterior (de menciones) la bola del @realmadrid será muy pequeña.
Pero ha ocurrido que ese tweet de la @casareal se ha retweeteado casi 2000 veces, un número muy alto. En este mapa que estamos construyendo ahora, este mérito por haber sido retweeteado tantas veces recae en el @realmadrid, que entonces aparecerá grande. Como vehículo de propagación de la información, ha sido realmente importante. Otra cosa es que no es en esta red un nodo relevante para la circulación de la información. Esto se reflejará en el mapa de la centralidad, donde de nuevo su tamaño será insignificante, como veremos después.
Identificación de comunidades:
Sobre este mapa, podemos identificar comunidades como aquellos grupos especialmente afines en su interior, que forman algo diferenciado del resto. Esto se hace en base a algoritmos matemáticos bien conocidos. Para visualizarlos mejor, pintamos cada comunidad con un color diferente (si hay muchas comunidades, algún color puede repetirse, claro)
Por ejemplo en una red así,
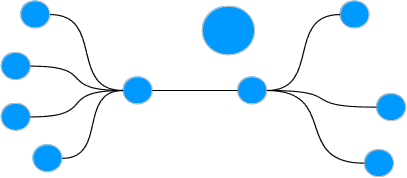
el sistema reconoce y colorea estas tres comunidades.
Para sistemas grandes la situación es mucho más compleja, pero puede llevarse a cabo con la ayuda de unos cuantos ordenadores.
Existen algoritmos precisos que identifican los grupos que colaboran más internamente entre ellos que con el exterior, los grupos que podemos considerar como comunidades formadas por personas más afines entre sí. Estas comunidades se han identificado en los mapas asignando un mismo color a los miembros de una misma comunidad.
Mapas Clusterizados
Para una mayor simplificación podemos dibujar solamente las comunidades identifcadas; es decir ahora cada bola representa a una comunidad entera, con un mombre corespondiente al usuario com más peso dentro de dicha comunidad. Existe una relacion entre dos comunidades si la hay entre alguno de sus miembros.
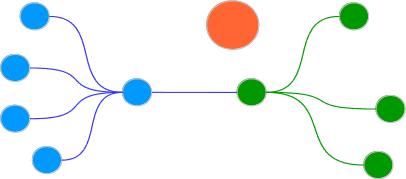
De nuevo sobre este mapa podemos identificar Comunidades y colorear las afines: Atencion ahora las comunidades de un mismo color son en realidad "comunidades de comunidades" Para la red del ejemplo anterior, el mapa clusterizado sería:

Notar como el sistema ha identificado incialmente tres comunidades, por tanto hay tres bolas, para luego identificar que dos de ellas forma a su vez una Comunidad de Comunidades, y las ha pintado del mismo color. La bola aislada es en si misma una comunidad aislada.
Mapas de Centralidad
En los mapas anteriores el tamaño de cada usuario es proporcional al numero de menciones o retweets. Pero las redes nos permiten ir mucho mas allá.
Una vez construido el mapa de menciones, nos podemos preguntar qué usuarios realizan un papel central, en el sentido de que son importantes para cohesionar grupos, catalizar opiniones, propagar información.
Esta idea general se concreta de la siguiente manera. Dado el mapa anterior, tomamos dos nodos al azar, y calculamos el camino más corto para ir de uno al otro, entendiendo que la longitud de cada link es la inversa de su intensidad: a más intensidad camino más corto (usuarios que se citan más). Tenemos así para cada par de usuarios el camino más corto que los une (geodésica).
Tomemos una geodésica concreta y apuntamos cada nodo por el que pasa. Tomamos todos los caminos, y sumamos para cada nodo el número de veces que hemos pasado por él. Este número es lo que llamaremos Centralidad.
Podemos dibujar el mapa anterior, pero ahora el tamaño de cada nodo lo hacemos proporcional a ucentralidad. Nodos que sirven de aglutinadores de grupos tendrán una centralidad alta, aunque tuvieran un grado (número de citas) bajo. Y nodos periféricos tendrán centralidad baja aunque tengan grado alto.
Aquí podemos ver que nodos con gran tamaño en el mapa de grado, al ser periféricos, aparecen como muy pequeños. Son nodos espurios, falsos, pero detectados automáticamente y en base a criterios precisos y muy bien definidos.
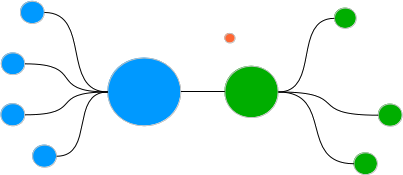
Pongamos un ejemplo; supongamos que la red de grado, es decir de menciones es así:
Identificamos las comunidades, y coloreamos, obteniendo entonces
Ahora calculamos la centralidad y ponemos el tamaño proporcional a la misma, con los mismos colores y la misma posición.
 Volver arriba
Volver arriba
